Upcycling Datasets for LLM Evaluation


- We use upcycling to describe the process of transforming raw, uneven datasets into high-quality calibrated item banks optimized for model evaluation.
- Trismik upcycles open datasets like MMLU-Pro, OpenBookQA, and PIQA into calibrated test banks.
- Schema transformation brings datasets into a standard format for discriminative multiple-choice tests (with future support for generative evals).
- Balanced distributions across question difficulties + quality goals ensure reliability, efficiency, and reproducibility.
Beyond classical benchmarks
Benchmark datasets play a critical role in evaluating large language models (LLMs) effectively. But in their raw form, they treat every item (or row in the data set) equally: a simple recall question like "What is the capital of India?" is considered equivalent to an advanced reasoning task. This wastes computing costs, slows experimentation, and hides important distinctions in model capability.
In this blog post we'll discuss how Trismik is taking an upcycling approach. Instead of just creating new benchmarks from scratch, we started by thinking about how we could enhance open datasets like MMLU-Pro, OpenBookQA, and PIQA. Using Item Response Theory (IRT), we convert them into calibrated item banks where each question's difficulty is known. With calibrated difficulty scores we can refine datasets by removing trivial or impossible items and identify gaps where we need to challenge stronger models.
It also opens up the possibility of hardening existing items, if existing ones have become too easy, say by adding more or better distractors in the case of multiple choice questions (MCQs).
Our LLM test banks are flexible: you can run classical tests on the full dataset or adaptive tests that adjust to model performance. The difficulty estimates for each question enable targeted evaluation, for example, testing only on "medium difficulty" items to understand model performance in that specific range, rather than averaging across easy and hard questions. Teams use our item banks to compare base models, detect regressions during fine-tuning, and evaluate LLM behaviour across skill-specific domains.
Deriving new versions of datasets
If you've ever tried to transform a public benchmark, you know how messy it can get. You're not alone, AI scientists across the field run into the same recurring challenges when preparing data for model evaluation. At Trismik, we've built tooling to tackle three of the most common pain points:
Schema transformation
Every dataset has its own quirks.
- MMLU-Pro stores answers as indices pointing to the correct answer
- OpenBookQA uses string labels and nested structures
- PIQA uses separate fields for each candidate answer.
Different datasets follow different structures and naming conventions. If you're trying to build standard multiple-choice tests from each of these, manual mapping becomes troublesome, especially at scale.
Here's a side-by-side look at raw formats from the above three datasets:
| Dataset | Example of raw format |
|---|---|
| MMLU-Pro | json { "question": "What is 2+2?", "choices": ["1","2","3","4"], "answer": 3 } |
| OpenBookQA | json { "question_stem": "Which gas is most responsible for trapping heat in the Earth's atmosphere?", "choices": [ {"label":"A","text":"Oxygen"}, {"label":"B","text":"Carbon Dioxide"}, {"label":"C","text":"Nitrogen"}, {"label":"D","text":"Argon"} ], "answerKey":"B"} |
| PIQA | json { "goal": "You want to prevent metal tools from rusting in storage.", "sol1": "Coat them lightly with oil before putting them away", "sol2": "Leave them damp after use so they don't dry out", "solution": 0 } |
And after our standardisation:
| Dataset | Example of standardised format |
|---|---|
| MMLU-Pro | json { "question": "What is 2+2?", "choices": ["1", "2", "3", "4"], "answer": "4" } |
| OpenBookQA | json { "question": "Which gas is most responsible for trapping heat in the Earth's atmosphere?", "choices": ["Oxygen", "Carbon Dioxide", "Nitrogen", "Argon"], "answer": "Carbon Dioxide" } |
| PIQA | json { "question": "You want to prevent metal tools from rusting in storage.", "choices": ["Coat them lightly with oil before putting them away", "Leave them damp after use so they don't dry out"], "answer": "Coat them lightly with oil before putting them away" } |
This standardised format ensures that all datasets share the same structure and field names, making them easier to process at scale without custom handling for each source.
What we do:
We convert everything into a shared schema tailored for fixed-choice (multiple-choice) tests. The process blends pattern matching, semantic alignment, and fallbacks that resolve the vast majority of cases automatically. It means you can go from raw data to a ready-to-use item bank in hours, not weeks.
We're also building support for generative test formats, because we know many teams want to evaluate long-form outputs too.
Rebalancing difficulty
Most datasets aren't balanced across the difficulty spectrum, some are skewed towards easy questions, or the kind of expert-only items that only a few frontier models can answer. And as models improve, this imbalance gets worse: yesterday's medium-difficulty questions become today's throwaways.
What we do:
We use statistical optimization to rebalance question difficulty across the full spectrum, from easy to challenging. That way, adaptive tests stay useful, model evaluations stay meaningful, and your comparisons stay fair.
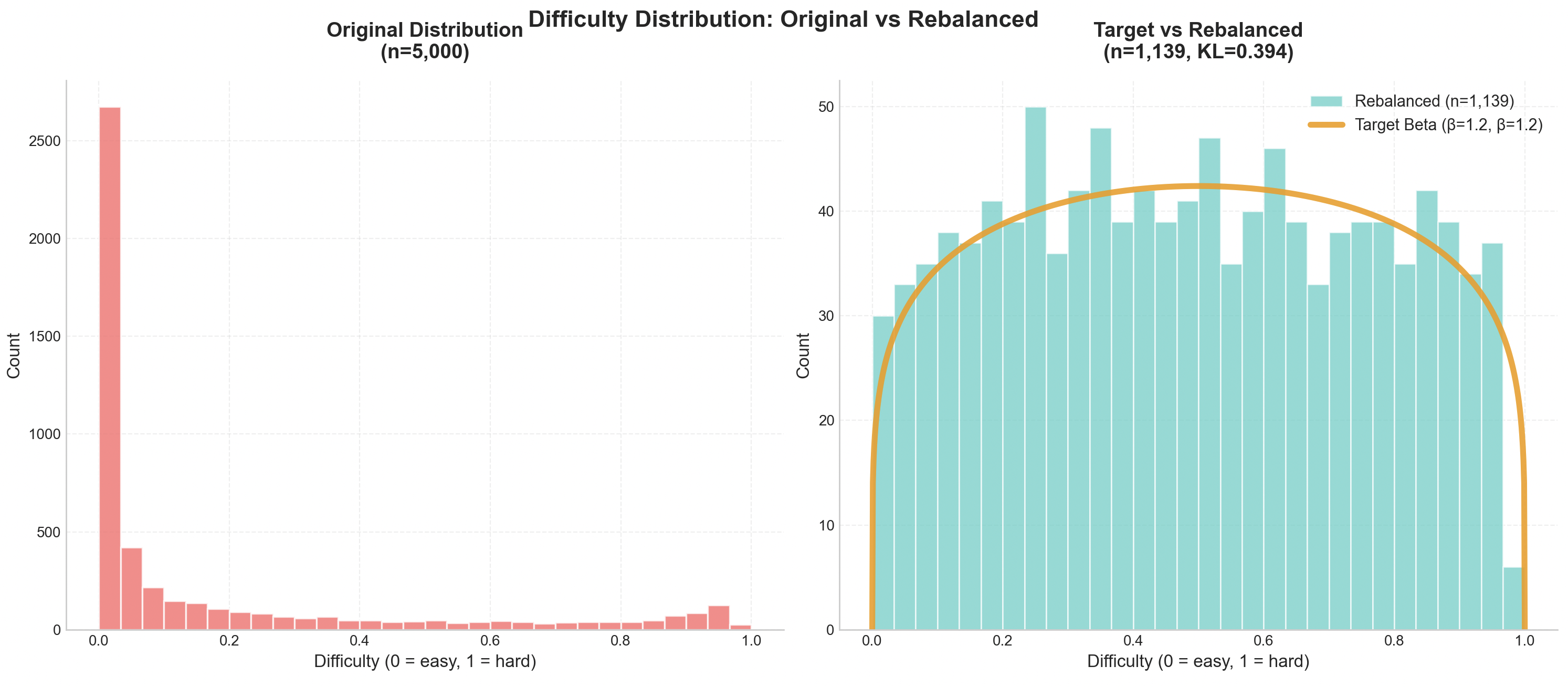
A random subsample of MMLU with difficulty estimates made in 2025. Notice the raw distribution contains a heavy skew towards easy items. Rebalancing to a beta(1.2,1.2) target loses most of the uninformative items but gives a smooth distribution across the difficulty spectrum.
Quality assurance
Once you start transforming datasets, quality risks creep in: duplicate items, broken fields, questionable licenses… It's easy for issues to go unnoticed until it's too late.
What we do:
We've baked quality checks into every step of our pipeline:
- Before processing: we check licenses, structure, and, as we move forwards, data health.
- During processing: we set budget caps and roll back on failure.
- After processing: we measure coverage, divergence, redundancy, and more.
And to keep things transparent, every dataset gets a data card so you can audit where it came from, how it was transformed, and what it measures. Our goal is to maintain 0% redundancy and 100% coverage of the skills being measured, while surfacing clear metrics so researchers can assess dataset quality directly.
Looking ahead
By upcycling open benchmarks with schema transformation, IRT calibration, and quality safeguards, we upcycle old data sets into high quality item banks. Paired with adaptive testing, this approach yields precise evaluations in fewer items, helping AI scientists trust what their models can (and cannot) do.
The datasets we've processed so far are just the beginning and we'll be adding more over the coming weeks and months. Creating high quality data costs effort and expense. As new benchmarks emerge in reasoning, multimodality, and specialized domains, this approach can help keep them valuable for future generations of LLMs.